|
I am a ELLIS PhD student at Marcus and Anna Rohrbach's Multimodal AI Lab. Previously, I was a research engineer on efficient deep learning at Huawei Zurich. I completed an MSc Machine Learning at University College London, graduating on the Dean's List (top 5%). During my MSc thesis, I was advised by Timoleon Moraitis and Pontus Stenetorp. Previously, I interned as a Software Development Engineer in Amazon Web Services, and obtained a BSc Theoretical Physics from UCL with first-class honours. |

|
|
I'm interested in improving the efficiency and reliability of Multimodal Large Language Models (MLLMs), especially when combined with reasoning and agentic tool use, and when dealing with text, images and video. Previously I have also worked in efficient brain-inspired deep learning. |
|
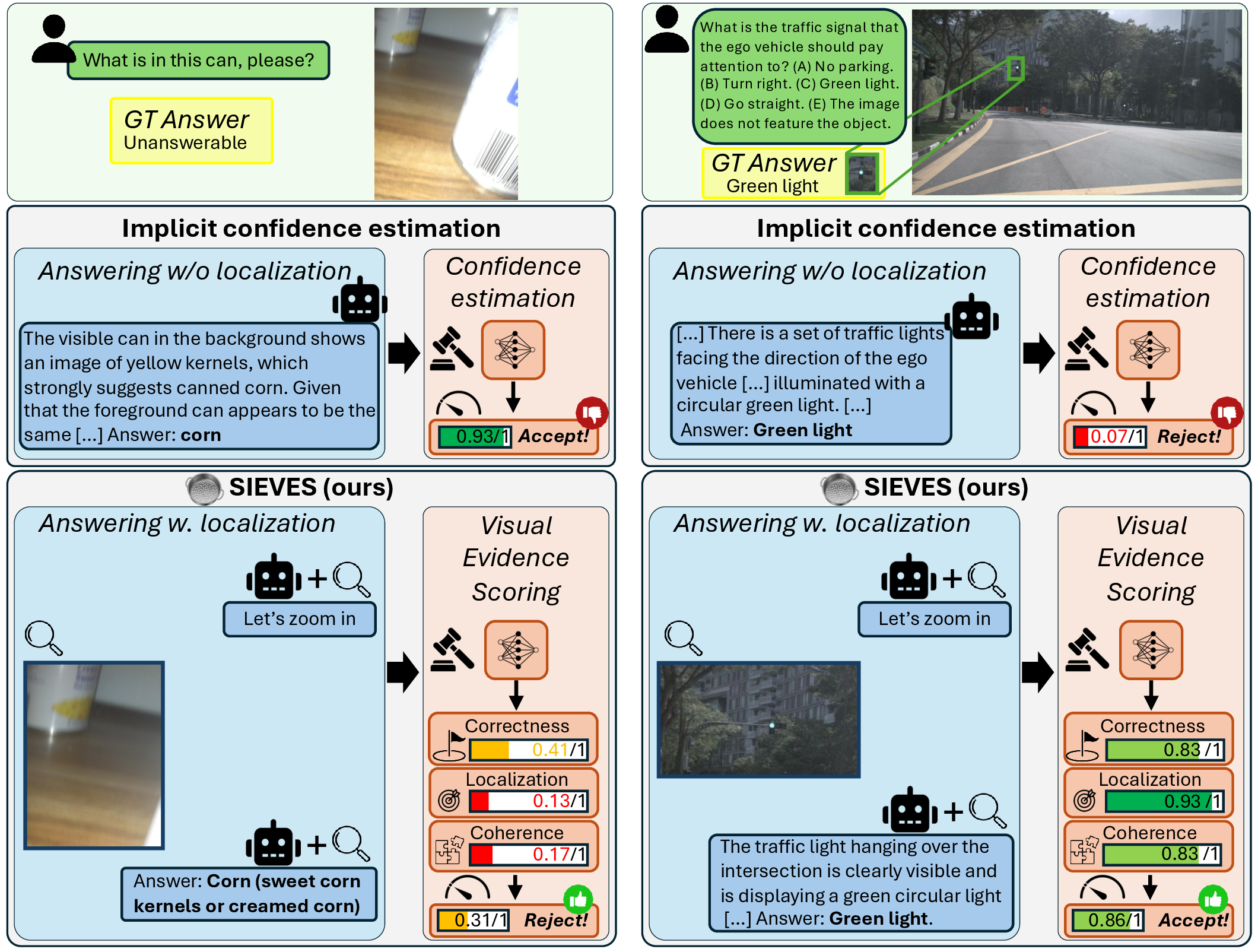
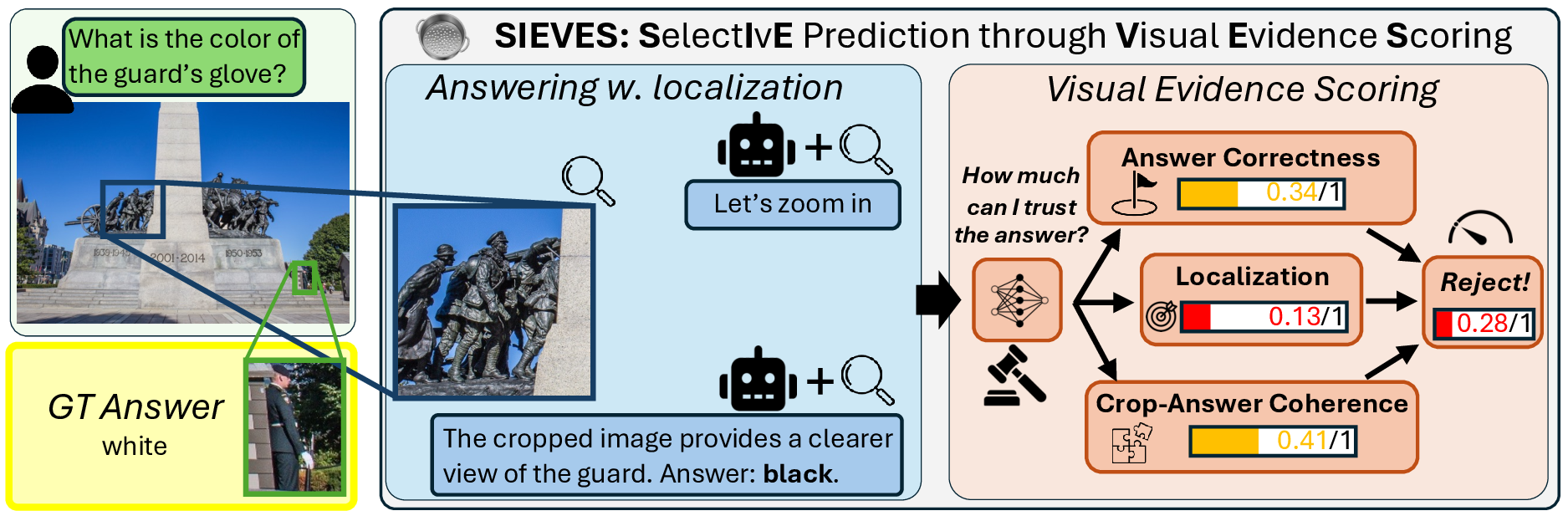
Hector Garcia Rodriguez, Marcus Rohrbach arXiv preprint, 2025 arXiv / code We leverage the visual evidence produced during multimodal reasoning, where models zoom into relevant image regions, to predict how confident a user can be in an answer provided by an MLLM and abstain on low confidence answers. To do so, we train a smaller model to predict fine-grained scores focusing on answer correctness (is the final answer reasonable?), localization (did the model look at the right place?) and crop-answer coherence (is the final answer coherent with the visual evidence?). SIEVES improves coverage by up to 3x on OOD benchmarks including visual questions from blind users and autonomous driving, where reliability of autonomous systems is crucial, and transfers to proprietary models like o3 and Gemini-3-Pro without accessing their internal representations or logits. |
|
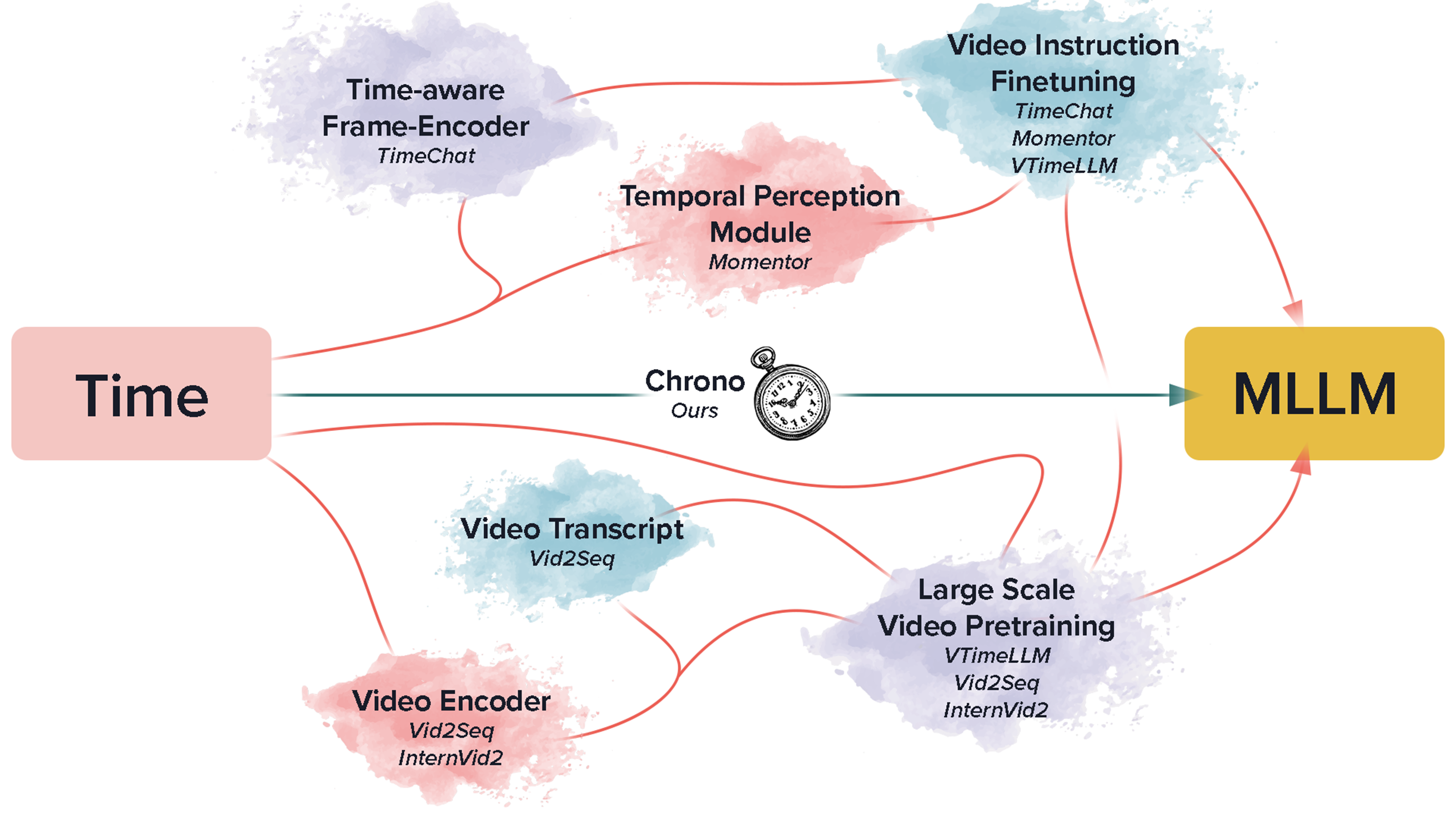
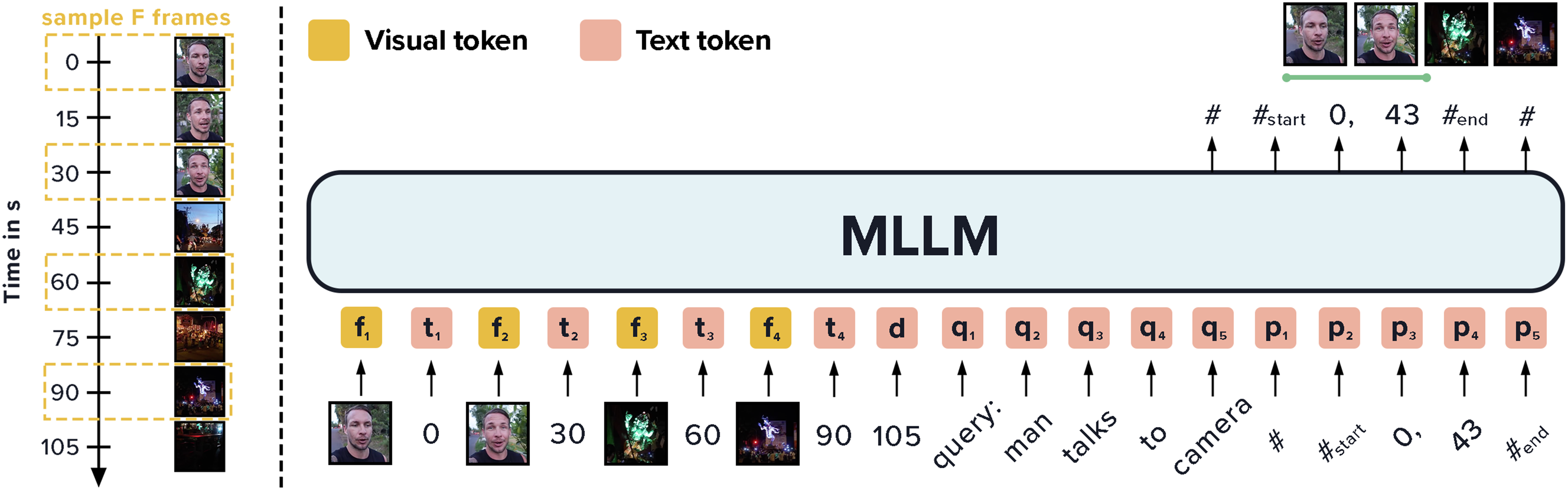
Hector Garcia Rodriguez*, Boris Meinardus*, Anil Batra, Anna Rohrbach, Marcus Rohrbach arXiv preprint (under review) arXiv / code We enable MLLMs to understand time in videos by timestamping. This achieves state-of-the-art on moment-retrieval (Charades-STA, QVHighlights, ActivityNet Captions) and grounded video QA (NExT-GQA), in both zero-shot (GPT-4o) and fine-tuned (BLIP-2) settings. |
 
|
Adrien Journé, Hector Garcia Rodriguez, Qinghai Guo, Timoleon Moraitis ICLR notable-top-25% (spotlight), 2023 arXiv / code / talk We train deep ConvNets with an unsupervised Hebbian soft winner-take-all algorithm, multilayer SoftHebb. It sets SOTA results in image classification in CIFAR-10, STL-10 and ImageNet for other biologically plausible networks. SoftHebb increases biological compatibility, parallelisation and performance of state-of-the-art bio-plausible learning. |
 
|
Hector Garcia Rodriguez, Qinghai Guo, Timoleon Moraitis ICML, 2022 arXiv / code / talk / poster / slides STPN is a recurrent neural network that improves Supervised and Reinforcement Learning by meta-learning to adapt its weights to the recent context, inspired by computational neuroscience. Additionally, STPN shows higher energy efficiency in a simulated neuromorphic implementation, due to its optimised explicit forgetting mechanism. |
{kind=link}
|
|